The Disruptor is, essentially, a scheduling strategy builder for multithreaded code. It stands out in the world of concurrent programming because it offers both great execution speed and easily readable and debuggable code. Yes, it does have a weird name. According to the original whitepaper, it was coined “Disruptor” because
it had elements of similarity for dealing with graphs of dependencies to the concept of “Phasers” in Java 7…
Of course, it is much more than just a Star Trek joke. The pattern was developed by the LMAX exchange to build a competitive, low-latency trading platform that could handle millions of transactions per second. Luckily for us developers, they have opened the source code to the public. The reference implementation is written in Java, but there is a C# implementation as well.
Under the hood, the Disruptor is a pre-allocated array used as a ring buffer where a process is applied each element in the buffer in order. The process is expressed as an acyclic dependency graph (DAG) of EventProcessors. Each EventProcessor should be thought of as a separate task or thread, since they are designed to be executed in parallel. After an EventProcessor finishes the work associated with an Event, it will advance its Sequence Barrier past that Event.
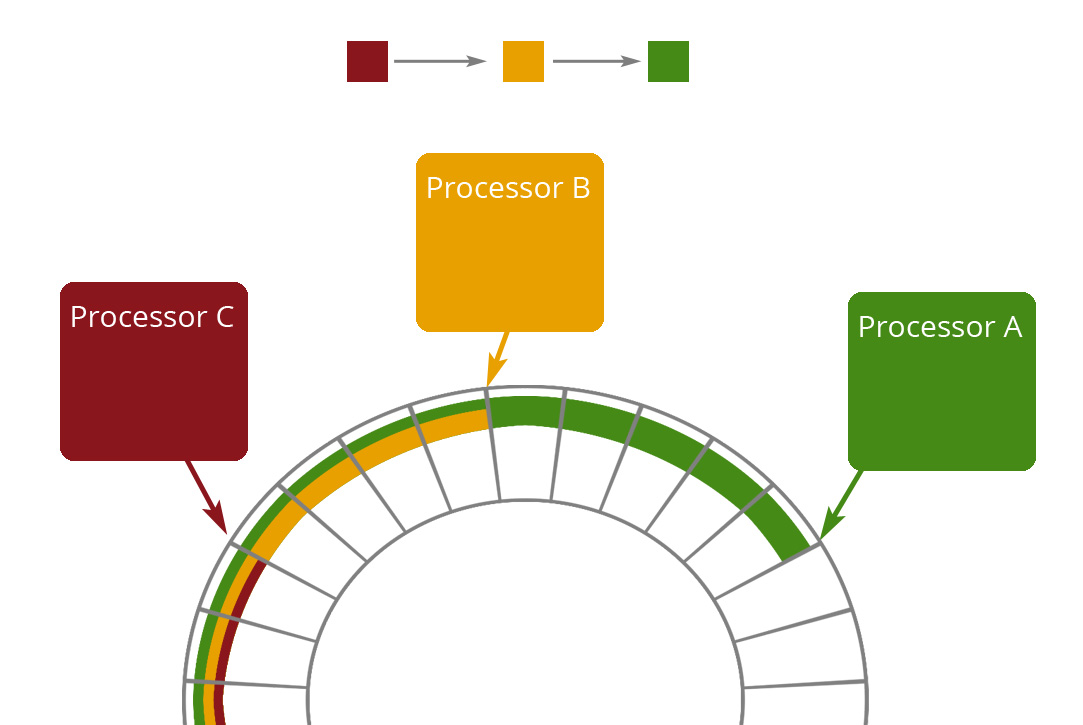
Fig. 1: C depends on B, B depends on A.
This allows other EventProcessors which depend on it to continue processing, up to the barrier. Since there is a single writer for each sequence barrier, no locks or CAS operations are required. A similar edict applies to Events themselves: each EventProcessor must only write to its own properties on an Event, or to events that it has been assigned to, making it a single writer for those events or those properties.
The Disruptor was intended to be a foundation for an extremely fast interactive application whose database fits in RAM, But in my experience, it can also be used as a good way to organize and optimize an asynchronous process involving external services and slow disks. It is best used in conjunction with event streams or message queues rather than a traditional 3-Tier architecture like MVC with a SQL backend.
A True Story (Some Names Changed)
Say a client, CodeExampleCorp, the premier provider of todo lists, wants to move their Customer Relationship Management to the cloud. The boss has decided that all todo lists will be replicated to TodoListForce.com, allowing sales reps to better assist customers.
However, the QA engineers discovered that TodoListForce.com will slow to a crawl if we send it an unbounded number of requests. During peak hours, the number of todo list updates greatly exceeds that threshold.
We needed a way of batching many individual requests into larger chunks while transforming their format, and it needed to be fast, both in terms of latency and throughput.
We decided to apply the disruptor to this stream processing problem because the requirements were constantly changing, and our initial solution using queues wasn’t flexible enough to keep up. We knew it would help us build our process quickly and keep it agile.
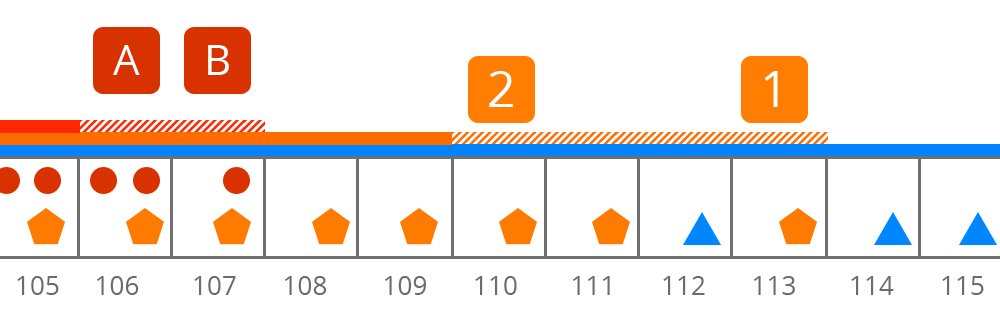
Two groups of
EventProcessors advancing along the ring buffer to the right and mutating events as they go. Each processor can run as a separate task or thread, however, they must never read or write to the same memory without being separated in the sequence. For example,1and2are separated by interleaving:1only processes odd events, and2only processes even events.AandBmodify different properties,Athe upper left, andBthe upper right. The groups[1, 2]and[A, B]are separated by aSequence Barrier.
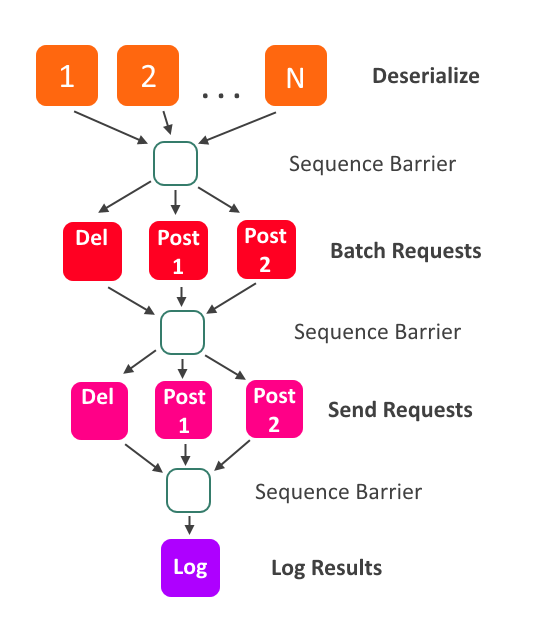
My code example shows a similar solution to the one we ended up with. Updates come in on the stream, and we have multiple processors working to deserialize them. After that, we split the updates up according to the request types that TodoListForce.com accepts, and batch them into larger requests. Finally, the requests are sent, and when finished, the results will be logged.
Each one of the colored boxes is an
EventProcessor, and the arrows represent ordering. For example, all deserializers must advance past an Event before the RequestBuilders are allowed to process it.
The process dependency graph is built with a fluent syntax:
var deserialize = GetDeserializers(numberOfDeserializers);
var groupIntoRequests = GetRequestBuilders(listsPerRequest);
disruptor.HandleEventsWith(deserialize)
.Then(groupIntoRequests);
// Since the Request Senders are AsyncEventProcessors
// instead of EventHandlers(synchronous)
// We have to manually create a sequence barrier
// and pass it in instead of just calling .Then() again.
var barrierUntilRequestsAreGrouped = disruptor
.After(groupIntoRequests)
.AsSequenceBarrier();
var sendRequests = GetRequestSenders(
ringBuffer,
barrierUntilRequestsAreGrouped,
RequestSenderMode.Callback
);
disruptor.HandleEventsWith(sendRequests);
var writeLog = GetFinalLoggingEventHandler();
disruptor.After(sendRequests)
.Then(writeLog);
var configuredRingBuffer = disruptor.Start();
I think it’s a good way of organizing a process. Each step in the process is encapsulated, and written to one common, flexible interface, the EventProcessor.
I think that flexibility is one of the disruptor pattern’s best features. If I wanted to join all request senders into one processor, I easily could. If I wanted to fuse the RequestBuilders and RequestSenders together, I could do that too. If I needed to insert a new step in the process, it would be trivial. Multiple input streams with different priority? No sweat.
This flexibility also makes it easy to optimize the process. In my example project, there is one NUnit test which configures the disruptor based on parameters and runs a load test for each combination of settings. The flexibility makes it easy to find big performance wins through experimentation. It only took me a few minutes to improve performance by a factor of 10 after writing the test.
This lock-free concurrency model enables us to write programs which, in theory, should scale near-linearly with number of processor cores. Since the future of computing looks more and more parallel, it’s likely that patterns like the Disruptor will become increasingly prominent.
In the end, it reached about 90 MB/s throughput, processing about 6000 requests per second on my laptop. Maybe nothing to write home about, but it’s approaching the speed required to handle something like the Twitter Firehose with a single node, and I think that’s good enough for a couple hours of work.
To get started with the Disruptor in .NET, download the NuGet package or check out my Todo List processing example on github.

Leave a Comment