I enjoy learning about all of the events in and around World War II, especially the Pacific theater.
I was reading the book Miracle at Midway by Gordon W. Prange (et. al.) and started to get curious about the pre- and post- histories of all the naval vessels involved in the Battle of Midway.
Historically, so many people, plans, and materials had to merge together at a precise moment in time in order for the Battle of Midway to be fought where it was and realize its radical impact on the outcome of World War II.
I got curious as to the pre- and post-history of all the people and ships that fought at Midway and wanted a way to visualize all of that history in a mobile application.
As a software guy, I started digging into possible data sources of ship histories. I was looking forward to constructing my vision of a global map view onto which I can overlay and filter whole historical data sets in and around naval vessels such as:
- Date of departure
- Date of arrival
- Location in lat / long of source / destination
- Other ships encountered during mission
- Mission being performed
- People who commanded and served
- People who may have been passengers or involved in the mission some way
I am not anywhere near constructing my vision of fully time and space dynamic filtered ship history maps yet. The keyword being: Yet.
This story details one tiny step I undertook to try and get to my goal against a found data source.
Finding a data source
I found a whole set of plain text ship histories as part of the Dictionary of American Naval Fighting Ships (DANFS).
An awesome Pythonista had already ripped the DANFS site content into a SQLite database which contains all 2000+ ship histories. – Thanks jrnold!
The ship histories are interesting to read but are not organized in a machine friendly format. The histories are largely just OCR’d text + a little HTML styling markup which was embedded as a side effect of the OCR process. I fully acknowledge that beggars can’t be choosers when it comes to data sources of this type. DANFS is as good a place to start as I could find this side of petitioning the National Archives for all naval ship logs. As any data scientist will tell you: You will spend 90% of your time cleaning your data, then 10% of your time actually using your data.
In this case, most of the ship histories are written in chronological order from past to present (once you separate out some header text regarding the background of the naming of the ship). In theory, if we just had a way to markup all the location names in the text, we could process through the text and create an in-order list of places that the ship has visited. Please note: All this is largely naive. It’s actually much more complicated than this, but you have to start somewhere.
Needless to say: I don’t want to do location identification by hand across 2,000+ free text ship histories. We are talking about the entire history of the American Navy. Having to classify and separate out locations by hand, by myself, is a huge task!
It turns out that there is a library that will markup locations within the text via an already trained machine learning based model: The Stanford Named Entity Recognizer (or Stanford NER)
Note: I continue in this post by using Stanford NER due to its C# / .NET compatibility. You may also want to check out Apache openNLP. Also keep in mind that you can also pre-process your data using NER / Natural Language Processing (NLP) and feed the results into ElasticSearch for even more server side search power!
DANFS History Snippet Before being run through Stanford NER:
<i>Abraham Lincoln </i>returned from her deployment to NAS Alameda on 9 October 1995. During this cruise, the ship provided a wide variety of on board repair capabilities and technical experts to 17 American and allied ships operating in the Middle East with limited or non-existent tender services. In addition, the Communications Department completed a telemedicine video conference with Johns Hopkins Medical Center that supported X-ray transfers and surgical procedure consultations.
DANFS History Snippet After Stanford NER:
<i>Abraham Lincoln</i> returned from her deployment to <LOCATION>NAS Alameda</LOCATION> on 9 October 1995. During this cruise, the ship provided a wide variety of on board repair capabilities and technical experts to 17 American and allied ships operating in the <LOCATION>Middle East</LOCATION> with limited or non-existent tender services. In addition, the <ORGANIZATION>Communications Department</ORGANIZATION> completed a telemedicine video conference with <ORGANIZATION>Johns Hopkins Medical Center</ORGANIZATION> that supported X-ray transfers and surgical procedure consultations.
Pretty cool, huh?
Notice the ORGANIZATION and LOCATION XML tags added to the text? I didn’t put those into the text by hand. Stanford NER took in the raw text from the ship history of the U.S.S. Abraham Lincoln (CVN-72) (Before) and used the machine learning trained model to markup locations and organizations within the text (After).
Machine Learning: Model = Sample Data + Training
From the documentation regarding the Stanford Named Entity Recognizer:
Included with Stanford NER are a 4 class model trained on the CoNLL 2003 eng.train, a 7 class model trained on the MUC 6 and MUC 7 training data sets, and a 3 class model trained on both data sets and some additional data (including ACE 2002 and limited amounts of in-house data) on the intersection of those class sets. (The training data for the 3 class model does not include any material from the CoNLL eng.testa or eng.testb data sets, nor any of the MUC 6 or 7 test or devtest datasets, nor Alan Ritter’s Twitter NER data, so all of these remain valid tests of its performance.)
3 class: Location, Person, Organization
4 class: Location, Person, Organization, Misc
7 class: Location, Person, Organization, Money, Percent, Date, Time
These models each use distributional similarity features, which provide some performance gain at the cost of increasing their size and runtime. Also available are the same models missing those features.
Whoa, that’s an academic mouthful. Let’s take a deep breath and try to clarify the Stanford Named Entity Recognizer pipeline:
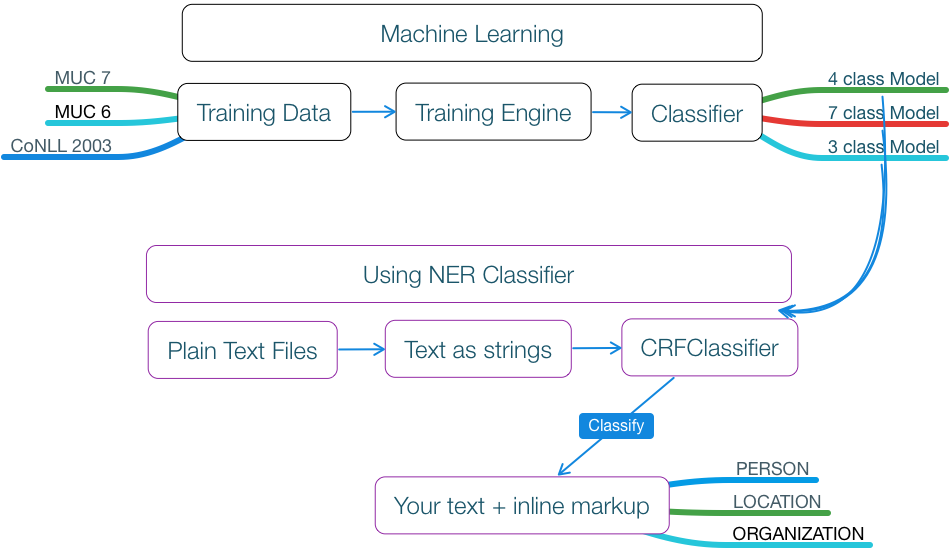
All the parts at the top of the diagram labelled ‘Machine Learning’ (with black borders) are already done for you. The machine learning + training output is fully encapsulated and ready for use via models available for download as a handy 170MB Zip file.
- When you crack open the model zip file, you will see the classifiers sub directory which contains the 4 class Model, 7 class Model, and 3 class Model:
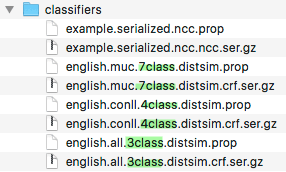
- It is one of these 3 models that you will use to initialize the CRFClassifier in your client code depending on your needs.

The parts at the bottom of the diagram in the ‘Using NER Classifier’ space (with purple borders) are what you will do in your client code to get person, location, and organization markup placed within your text. Check out the instructions on how to do this in C# / .NET.
The key to the client code is the CRFClassifier from the Stanford.NER.NLP NuGet Package. The CRFClassifier takes in your text and the trained model output file, from the above zip file, to do classification of person, location, and organization within your text.
// Loading 3 class classifier model
var classifier = CRFClassifier.getClassifierNoExceptions(
classifiersDirecrory + @"\english.all.3class.distsim.crf.ser.gz");
var s1 = "Good afternoon Rajat Raina, how are you today?";
Console.WriteLine("{0}\n", classifier.classifyToString(s1));
Cleaning the data
Cleaning a set of OCR’d free form text files and converting it to a format that makes it easy for a developer to process it using code can be difficult. Data cleaning is an ad-hoc process requiring use of every data processing, and possibly coding, tool you have in your tool belt:
- Regular Expressions
- String replacement
- XML DOM traversal
- Node + attribute add
- Node + attribute remove
- Standard string split and replacement operations
- Log to console during processing and manually create filtered lists of interesting data.
- These lists can also be fed back as training data for future machine learning runs.
- Filter values on created lists from source data.
- Use of trained models
All that said, Named Entity Recognition gives you a fun and solid starting point to start cleaning your data using the power of models from machine learning outputs.
I highly recommend using Stanford NER as one or more stages in a pre-production data cleaning pipeline (especially if you are targeting the data for rendering on mobile platforms).
Beware: your data may have a series of false positive PERSON, ORGANIZATION, or LOCATION tags written into it by Stanford NER that may have to be filtered out or augmented by additional post-processing.
In my case Stanford NER also marks up the names of people in the text with PERSON XML tags. You may notice that Abraham Lincoln above is part of a ship name and also the name of a person. In my first run of this ship history text through Stanford NER, the text Abraham Lincoln was surrounded by PERSON XML tags. Having 1,000 occurrences of the person ‘Abraham Lincoln’ in a ship history about the U.S.S. Abraham Lincoln is probably not very useful to anyone. I had to run a post-processing step that used the XML DOM and removed any PERSON, ORGANIZATION, or LOCATION tags if the parent of those tags was an ‘i‘ tag. I found that ‘i‘ tag was written into the original history text from DANFS to indicate that it is a ship name so it was the easiest (and only) data marker I had to aid in cleaning. The same problem would occur for the U.S.S. Arizona, U.S.S. New Jersey, U.S.S. Missouri, and other text where locations, people, or organizations were used as ship names.
I fully intend on trying to use machine learning, and alternate training sets for Stanford NER, to ensure that PERSON, ORGANIZATION, and LOCATION tags are not written if the text is within an ‘i’ tag (but haven’t done this yet).
As I was cleaning the data using Stanford NER I ran across instances where the rank or honorific of a person was not included within the PERSON tag:
Capt. <PERSON>William B. Hayden</PERSON>
My initial implementation to include the honorific and/or rank of the person was problematic.
- After the NER stage, I scan through the XML output using System.Xml.Linq (i.e. XDocument, XNode, XElement) looking for any PERSON tags.
- Using the XML DOM order I went to the previous text node right before the start PERSON tag.
- I then displayed the first 3 words, as split by a space, at the end of the preceding text node.
In my naiveté I figured that the honorific and/or rank would be at worst about 50 different 3 word variations. Things like:
- Private First Class
- Lt. Col.
- Col.
- Gen.
- Maj. Gen.
- Capt.
Well imagine my astonishment when I discover that the DANFS data doesn’t only contain the names and honorifics of military personnel; but of passengers and people in and around the history of the ship:
- Senator
- Sen.
- King
- Queen
- Princess
- Mrs.
- Representative
- Congressman
- …. and many, many, many more
In addition I found out that almost every possible abbreviation exists in the ship history text for rank:
- Lt.
- Lieutenant
- Lieut.
- Commander
- Cmdr.
My second pass at determining the honorific of a person may just involve a custom training stage to create a separate ‘Honorific’ model trained by the set of honorific data I have derived by hand from the whole DANFS text data set.
As stated above: Data scientists spend way too much time cleaning data using any technique that they can. On this project, I found that I was never really ever done extracting new things from the data, then cleaning the output data some more in a never ending loop.
I hope in the future to provide all the sample cleaned DANFS data, my data cleaning source code, and a sample mobile app that will interactively render out historical ship locations.

Leave a Comment